

- HA機能の追加(データノードの冗長化)
- LinuxおよびWindows用ビルド済みMySQLパッケージの配布
インストールが簡単になった!
前回SPIDERストレージエンジンを紹介したときには、ソースコードからコンパイルする必要があり、なおかつMySQL本体にパッチを適用しなければならず、利用するまでの敷居が高かったように思う。しかし、バージョン2.22よりSPIDERを含んだビルド済みバイナリが提供されたことにより、SPIDERを利用する手間はぐっと少なくなった。しかもこのビルド済みのバイナリにはSPIDERだけでなく各種パッチと、さらにはVPストレージエンジンまで含まれているという気の利きようだ。コンパイルが面倒だから・・・とこれまで利用を躊躇していた人は、ぜひこの機会にSPIDERを試してみて頂きたい!ビルド済みバイナリは次のページで配布されている。
Spider for MySQL / launchpad
https://launchpad.net/spiderformysql
http://launchpad.net/spiderformysql/spider-2.x/2.23-for-5.1.44/+download/spider-init-2.23-for-5.1.44.tgz
今回のエントリでは最新バージョン(昨夜リリースされた)である2.23を利用する。バイナリの種類はWindows 32ビット版、Linux 32ビット版/64ビット版がある。例えばLinux 64ビット版であればmysql-5.1.44-spider-2.23-vp-0.12-linux-x86_64-glibc23.tgzをダウンロードしよう。利用方法は通常のtar.gz版MySQLバイナリ(Windowsの場合はzip版)と同じ。つまりどこかへ展開すればOKだ!
例によってMySQL::Sandboxを使ってインストールする。今回はノード数8でインストールしてみよう。
shell> mv mysql-5.1.44-spider-2.23-vp-0.12-linux-x86_64-glibc23.tgz mysql-5.1.44-spider-2.23-vp-0.12-linux-x86_64-glibc23.tar.gz shell> make_multiple_sandbox --how_many_nodes=8 mysql-5.1.44-spider-2.23-vp-0.12-linux-x86_64-glibc23.tar.gzMySQL::Sandboxのmulti_msb_5_1_44では、各サーバーに個別のserver_idを割り振ってくれる。SPIDERのHA機能ではserver_idを利用するので、MySQL::Sandboxを利用しない場合には、手動でserver_idを割り振ろう。
SPIDER初期化用のスクリプト(管理テーブルの作成やプラグインのロード)も配布されており、インストールにはこちらも必要となる。spider-init-2.22-for-5.1.44.tgzをダウンロードして展開しよう。すると、install_spider.sqlというファイルが現れるので、これをすべてのノードで実行しよう。
shell> tar xf spider-init-2.22-for-5.1.44.tgz -C $HOME/sandboxes/multi_msb_5_1_44 shell> cd $HOME/sandboxes/multi_msb_5_1_44 shell> ./use_all 'source install_spider.sql'最後にVPストレージエンジンをロードすれば作業は完了である。
mysql> install plugin vp soname 'ha_vp.so'; mysql> create function vp_copy_tables returns int soname 'ha_vp.so';
HA機能の利用
SPIDERのHA機能は2つのデータノードへ完全にデータをミラーリングする。そして、モニタリングノードと呼ばれるノードを用い、データノードの監視を行うのである。モニタリングノードは最低3台必要であり、多数決によってHAのステータスを決定する。データへアクセスするSPIDERノードは、モニタリングノードにステータスを問い合せて各データノードが生きているかどうかを判断するのである。今のところ、問題のあるデータノードが切り離されるのは自動で行われるがリカバリは手動となる。なお、モニタリングノード自身もデータへ参照することが出来るので、実質的には3台以上のモニタリングノードと、2台以上のデータノードがHAを構成する上で最低限必要となる。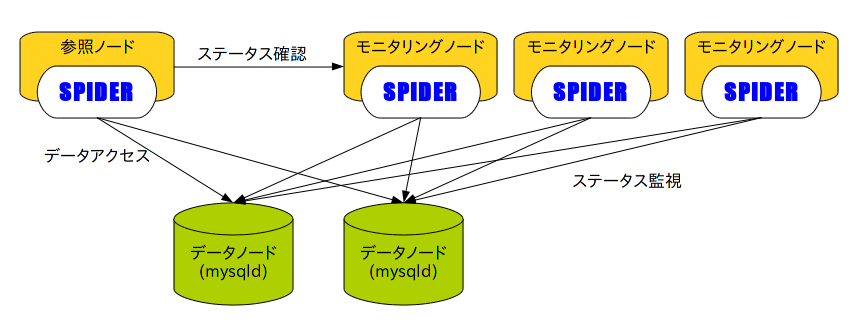
それでは早速HA機能を使ってテーブルを作成してみよう。まずはテーブル定義を簡略化するためのSERVERオブジェクトの作成である。この辺は以前書いたエントリと共通なのでそちらも参照して頂きたい。
./use_all "CREATE SERVER n1 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16545); CREATE SERVER n2 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16546); CREATE SERVER n3 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16547); CREATE SERVER n4 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16548); CREATE SERVER n5 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16549); CREATE SERVER n6 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16550); CREATE SERVER n7 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16551); CREATE SERVER n8 FOREIGN DATA WRAPPER mysql OPTIONS (USER 'msandbox', PASSWORD 'msandbox', HOST '127.0.0.1', PORT 16552)"今回作成するシステムのレイアウトは次の通りである。

まずはn5〜n8でHA化するためのデータの受け皿となるテーブルを作成しよう。今回利用するのはMySQLの公式サンプルデータベースであるworldデータベースのCountryテーブルをInnoDB化したものである。
shell> ./n5 test -e "CREATE TABLE `Country` (
`Code` char(3) NOT NULL DEFAULT '',
`Name` char(52) NOT NULL DEFAULT '',
`Continent` enum('Asia','Europe','North America','Africa','Oceania','Antarctica','South America') NOT NULL DEFAULT 'Asia',
`Region` char(26) NOT NULL DEFAULT '',
`SurfaceArea` float(10,2) NOT NULL DEFAULT '0.00',
`IndepYear` smallint(6) DEFAULT NULL,
`Population` int(11) NOT NULL DEFAULT '0',
`LifeExpectancy` float(3,1) DEFAULT NULL,
`GNP` float(10,2) DEFAULT NULL,
`GNPOld` float(10,2) DEFAULT NULL,
`LocalName` char(45) NOT NULL DEFAULT '',
`GovernmentForm` char(45) NOT NULL DEFAULT '',
`HeadOfState` char(60) DEFAULT NULL,
`Capital` int(11) DEFAULT NULL,
`Code2` char(2) NOT NULL DEFAULT '',
PRIMARY KEY (`Code`)
) ENGINE InnoDB CHARACTER SET utf8"
shell> ^n5^n6
shell> ^n6^n7
shell> ^n7^n8
次に、参照側のノードであるn1〜n4においてモニタリングノードの設定を行なおう。shell> ./n1 -e "insert into mysql.spider_link_mon_servers
(db_name, table_name, link_id, sid, server)
values
('world', 'Country#P#p1', 0, 101, 'n1'),
('world', 'Country#P#p1', 0, 102, 'n2'),
('world', 'Country#P#p1', 0, 103, 'n3'),
('world', 'Country#P#p2', 0, 101, 'n1'),
('world', 'Country#P#p2', 0, 102, 'n2'),
('world', 'Country#P#p2', 0, 103, 'n3'),
('world', 'Country#P#p1', 1, 101, 'n1'),
('world', 'Country#P#p1', 1, 102, 'n2'),
('world', 'Country#P#p1', 1, 103, 'n3'),
('world', 'Country#P#p2', 1, 101, 'n1'),
('world', 'Country#P#p2', 1, 102, 'n2'),
('world', 'Country#P#p2', 1, 103, 'n3')"
shell> ^n1^n2
shell> ^n2^n3
shell> ^n3^n4
spider_link_mon_serversテーブルには、パーティションごと、データノードごと、モニタリングノードごとにひとつのエントリが必要になる。今回はパーティションが2つ、それぞれのパーティションごとにデータノードが2つ(p1がn5、n6で冗長化、p2がn7、n8で冗長化)、そしてモニタリングノードは3つなので、2 x 2 x 3 = 12のエントリを追加する必要がある。パーティションを作成した場合、テーブルのエントリ名は「テーブル名#P#パーティション名」となる。仕上げとして、n1〜n4でSPIDERテーブルを作成する。以上でテーブルの設定はOKである。あとは通常のテーブルと同じように利用しよう。
mysql> "CREATE TABLE `Country` (
`Code` char(3) NOT NULL DEFAULT '',
`Name` char(52) NOT NULL DEFAULT '',
`Continent` enum('Asia','Europe','North America','Africa','Oceania','Antarctica','South America') NOT NULL DEFAULT 'Asia',
`Region` char(26) NOT NULL DEFAULT '',
`SurfaceArea` float(10,2) NOT NULL DEFAULT '0.00',
`IndepYear` smallint(6) DEFAULT NULL,
`Population` int(11) NOT NULL DEFAULT '0',
`LifeExpectancy` float(3,1) DEFAULT NULL,
`GNP` float(10,2) DEFAULT NULL,
`GNPOld` float(10,2) DEFAULT NULL,
`LocalName` char(45) NOT NULL DEFAULT '',
`GovernmentForm` char(45) NOT NULL DEFAULT '',
`HeadOfState` char(60) DEFAULT NULL,
`Capital` int(11) DEFAULT NULL,
`Code2` char(2) NOT NULL DEFAULT '',
PRIMARY KEY (`Code`)
) ENGINE SPIDER PARTITION BY KEY(Code) PARTITIONS 2
(
PARTITION p1 COMMENT 'table "Country", server "n5 n6", mbk "2", mkd "2", msi "101", link_status "1 1"',
PARTITION p2 COMMENT 'table "Country", server "n7 n8", mbk "2", mkd "2", msi "101", link_status "1 1"'
);
※n1〜n4で繰り返し。
mbk、mkd、msi、link_statusの意味については以下の通り。(ドキュメントより抜粋)・link_status(lst) リモートサーバへのリンクの状態を設定する。 このパラメータは、変更しなくてもALTER TABLEを実行する度にステータスの再設定を 行う。 0:設定しない。 1:正常。(更新も参照も行う) 2:リカバリ中。(更新は行うが参照は行わない。PKありテーブルのみ) 3:異常。(更新も参照も行わない) デフォルト値は 0 ・monitoring_bg_kind(mbk) テーブルのバックグラウンド死活監視種別。 0:監視しない。 1:接続の監視のみを行う。 2:where句なしでテーブルの監視を行う。 3:where句ありでテーブルの監視を行う。(まだ未対応です) デフォルト値は 0 ・monitoring_kind(mkd) テーブルの死活監視種別。 0:監視しない。 1:接続の監視のみを行う。 2:where句なしでテーブルの監視を行う。 3:where句ありでテーブルの監視を行う。(まだ未対応です) デフォルト値は 0 ・monitoring_server_id(msi) テーブルの死活監視の際に最初に接続する監視用MySQLサーバのID。 デフォルト値は 自サーバIDlink_statusパラメーターは並び順通りにserverパラメーターに対応している。上記の例では、パーティションp1のlink_statusはそれぞれn5、n6に対応しているのである。実は、以降で述べる障害の復旧シナリオなどでは、link_statusを0に設定するという手順が必要になる。link_statusを0に設定するとどうなるかということは、最初よく分からなかったのだが、「ステータスを変更しない」という意味だ。つまり、元々1であれば0を設定しても元々のステータスである1が設定されるわけである。
その他のパラメーターについてはspider-doc-2.23-for-5.1.44.tgzに含まれる06_table_parameters.txtを参照のこと。
障害からの復旧
HAである以上、サーバーに障害が生じてから復旧するためのシナリオを考えておく必要がある。例えばn5が壊れてしまったとしよう。すると、p1のlink_statusは「3 1」となるだろう。復旧時にはデータの再同期が必要となる。他のノードを利用しても構わないが、今回はn5を再起動した後にデータの再同期を行うこととする。まずはn5のデータを初期化しよう。shell> ./n5 test -e 'truncate Country'次に、データの再同期を行なう。
shell> ./n1 test mysql> "ALTER TABLE Country ENGINE SPIDER PARTITION BY KEY(Code) PARTITIONS 2 ( PARTITION p1 COMMENT 'table "Country", server "n5 n6", mbk "2", mkd "2", msi "101", link_status "2 0"', PARTITION p2 COMMENT 'table "Country", server "n7 n8", mbk "2", mkd "2", msi "101", link_status "0 0"' )" mysql> SELECT spider_copy_tables(‘Country’, ‘1’, ‘0’);spider_copy_tablesは成功すると1、失敗すると0を返す。成功したことを確認したら次のようにステータスを更新しれば作業は完了である。
mysql> "ALTER TABLE Country ENGINE SPIDER PARTITION BY KEY(Code) PARTITIONS 2 ( PARTITION p1 COMMENT 'table "Country", server "n5 n6", mbk "2", mkd "2", msi "101", link_status "1 0"', PARTITION p2 COMMENT 'table "Country", server "n7 n8", mbk "2", mkd "2", msi "101", link_status "0 0"' )" ※n1〜n4で繰り返し。







1 コメント:
Okunoさん、はじめましてOkuboと申します。
Spiderを試してみたく、ブログを拝見していたのですがうまくいかず。お助け願いたい
です。
手順に書いてあることは、実施したつもりですが、CountryテーブルをSelectしてみると
spider_link_mon_serversにレコードが無いと言われます。spider_link_mon_serversが空
かと言うと、selectしてみるとレコードがあるので、エラーの理由が判りません。
$ ./n1 mysql
node1 [localhost] {msandbox} (mysql) > select * from mysql.Country;
ERROR 1032 (HY000): Can't find record in 'spider_link_mon_servers'
node1 [localhost] {msandbox} (mysql) > select count(1) from mysql.spider_link_mon_servers;
+----------+
| count(1) |
+----------+
| 12 |
+----------+
1 row in set (0.00 sec)
手順が間違えているか不足していると思われますので、お手数ですが良く判らなかったところ
について、教えていただけないでしょうか。
1)ユーザの作成、cnfの書き換えが必要?
ユーザは、msandboxを使う。confは、Sandboxでインストールされたまま。
としましたが、それで問題ありませんか。
2)pluginの設定方法
> 最後にVPストレージエンジンをロードすれば作業は完了である。
> # mysql> install plugin vp soname 'ha_vp.so';
ha_vp.soは、どのn1〜n4ノードに入れれば良いですか?
また、plugin_dirをcnfに記述が必要ですか。
3)spider_link_mon_serversの設定値
> 次に、参照側のノードであるn1〜n4においてモニタリングノードの設定を行なおう。
> # shell> ./n1 -e "insert into mysql.spider_link_mon_servers
> # (db_name, table_name, link_id, sid, server)
> # values
> # ('world', 'Country#P#p1', 0, 101, 'n1'),
db_nameのworldって、変えなくても良いですか?
4)各テーブルを、どのDBに作るのか
> まずはn5〜n8でHA化するためのデータの受け皿となるテーブルを作成しよう。
> # shell> ./n5 test -e "CREATE TABLE `Country` (
"test"に作る?
> 仕上げとして、n1〜n4でSPIDERテーブルを作成する。
> # mysql> "CREATE TABLE `Country` (
どのDBに作りますか?
コメントを投稿